

What heartbreak with ULMFiT feels like
What heartbreak with ULMFiT feels like
And how I plan to celebrate my Valentine's


Contents
What is ULMFiT?
How to use ULMFiT?
How it broke my heart
What is ULMFiT?
Universal Language Model Fine-tuning for Text Classification
Inductive transfer learning has greatly impacted computer vision, but existing approaches in NLP still require task-specific modifications and training from scratch. We propose Universal Language Model Fine-tuning (ULMFiT), an effective transfer learning method that can be applied to any task in NLP, and introduce techniques that are key for fine-tuning a language model. Our method significantly outperforms the state-of-the-art on six text classification tasks, reducing the error by 18-24% on the majority of datasets. Furthermore, with only 100 labeled examples, it matches the performance of training from scratch on 100x more data. We open-source our pretrained models and code.
ULMFiT is a language model that leverages transfer learning in NLP. Previously, in the dark ages, there was a huge problem with using transfer learning in NLP. It was difficult because pretraining the entire model meant that the gradients would disappear. Also if you wanted to train a model from scratch, you’d need a lotttt of data.
ULMFiT’s novel contribution was its training and fine-tuning strategy.
Train a Language Model (LM) on very large generalised dataset. (Something like Wikipedia corpus)
Then gradually unfreeze the layers to finetune the LM on a domain-specific dataset
Train it for your downstream task like classification
Voila, you can now get state of the art results with your tiny little dataset
How to use it?
Here are the general steps:
Creating a DataBunch from pandas data frame
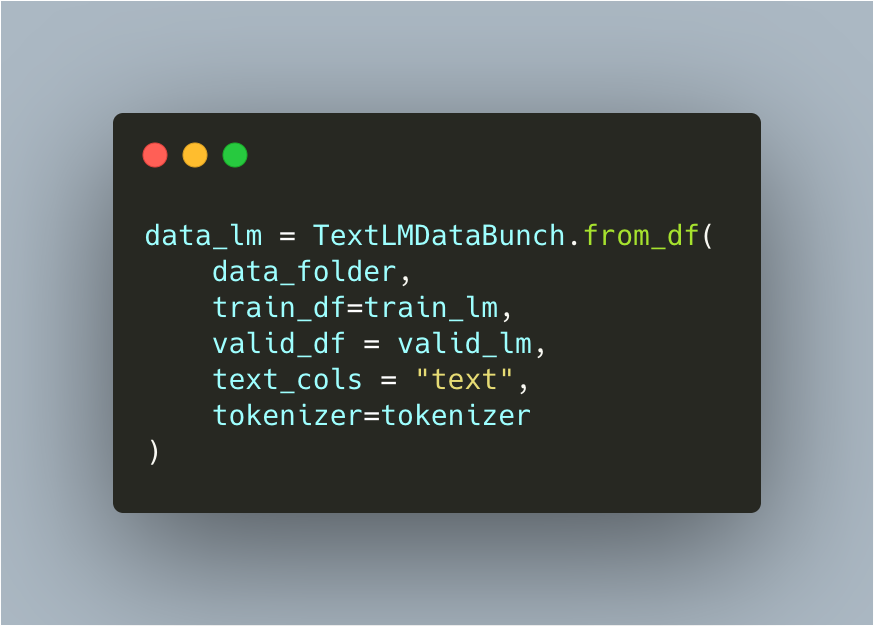
Then create a learner
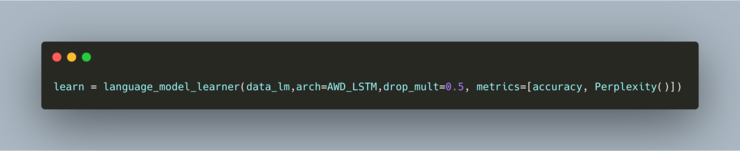
Train it using freezing and unfreezing (or as my roommate calls it, thawing)

Save the encoder

Create a data-bunch for classification task

Load the encoder and train the model
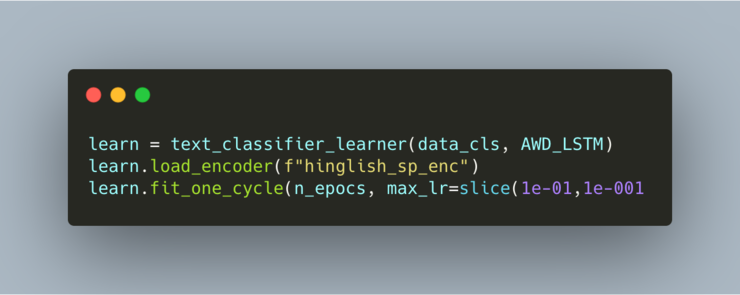
How it broke my heart
ULMFiT or transfer learning is 💙 for low resource data. You have a few hundred samples, you can always train it on Wikipedia and then downstream it to your domain data.
I decided to use it on my dataset which was Twitter Hinglish data.
It did really badly.
So I tried some tricks.
Tricks to use ULMFiT more efficiently:
Use gradual unfreezing. i.e Freeze top n layers while training and unfreeze a few bottom ones
Make sure your data is clean before giving it to the language model (for Twitter data, replace @ with ‘mention’, remove URLs and stuff)
See if your Vocab file is the same from classifier and LM (yes, I forgot about this; yes, I spent 30 minutes trying to figure out why I couldn’t load the encoder)
Use sentence-piece tokenizer instead of the traditional one (sentence piece uses subwords—they are kind of better)
My accuracy did increase with these changes, but not enough. My model was still performing worse than BERT. ULMFiT would saturate at 0.55 while BERT gave an accuracy of 0.64.
Language Model with a lot of unstructured Twitter data:
train_loss ~ 0.43 | valid_loss ~ 0.42 | accuracy ~ 0.28 | perplexity ~ 88.85
Language Model fine-tuned with target Twitter data (sentiment classification):
train_loss ~ 0.400 | valid_loss ~ 0.409 | accuracy ~ 0.30
Classification Model using the previous LM encoder for classification:
train_loss ~ 0.95 | valid_loss ~ 0.93 | accuracy ~ 0.55
I don't really know any other way (for now) to get it to perform better. However, I'll keep you updated about this.
For now, I am heartbroken because of ULMFiT because it was supposed to be my LM in the shining armour.